Part of a recent assignment for one of my classes involved calculating the Fibonacci sequence both recursively and iteratively and measuring the speed of each method. (BONUS: For a fun diversion, here is a paper I wrote about using the Golden Ratio, which is closely related to the Fibonacci sequence, as a base for a number system). In addition, we were supposed to pass the actual calculation as a function pointer argument to a method that measured the execution time.
The task was fairly straight forward, so I fired up Visual Studio 2015 and got to work. I usually target x64 during development (due to some misguided belief that the code will be faster), and when I ran the code in release mode I received the following output as the time needed to calculate the 42nd Fibonacci number:
Recursive: 0.977294758 seconds
Iterative: 0.000000310 seconds
Since calculating $F_{42}$ through naive recursion requires ~866 million function calls, this pretty much jived with my expectations. I was ready to submit the assignment and close up shop, but I decided it’d be safer to submit the executable as as 32-bit application. I switched over to x86 in Visual Studio, and for good measure ran the program again.
Recursive: 0.000000000 seconds
Iterative: 0.000000311 seconds
Well then. That was… suspiciously fast. For reference, here is (a stripped down version of) the code I was using.
#include <iostream>
#include <iomanip>
#include <chrono>
#include <cassert>
constexpr int MAX_FIB_NUM = 42;
constexpr int F_42 = 267914296;
int fib_recursive(int n)
{
if (n < 2)
return n;
else
return fib_recursive(n - 1) + fib_recursive(n - 2);
}
int fib_iterative(int n)
{
int f_1 = 1, f_2 = 0;
for (int i = 1; i < n; ++i)
{
int tmp = f_1;
f_1 = f_1 + f_2;
f_2 = tmp;
}
return f_1;
}
double measure_execution_time(int(*func)(int))
{
auto start = std::chrono::high_resolution_clock::now();
int ret = func(MAX_FIB_NUM);
auto end = std::chrono::high_resolution_clock::now();
assert(ret == F_42);
return std::chrono::duration<double>(end - start).count(); //convert to fractional seconds
}
int main(int argc, char** argv)
{
auto recursive_duration = measure_execution_time(fib_recursive);
auto iterative_duration = measure_execution_time(fib_iterative);
std::cout << std::setprecision(9) << std::fixed; //up to nanoseconds
std::cout << "Recursive: \t" << recursive_duration << " seconds " << std::endl;
std::cout << "Iterative: \t" << iterative_duration << " seconds " << std::endl;
return 0;
}
In debug mode the code took the expected amount of time; only the release build targeting x86 was exhibiting the seemingly blazingly fast performance. What was happening here? Some constexpr magic resulting in the compiler precomputing the answer? An overly aggressive reordering of the now() calls?
To figure out the answer I opened the executable in IDA and started poking around.
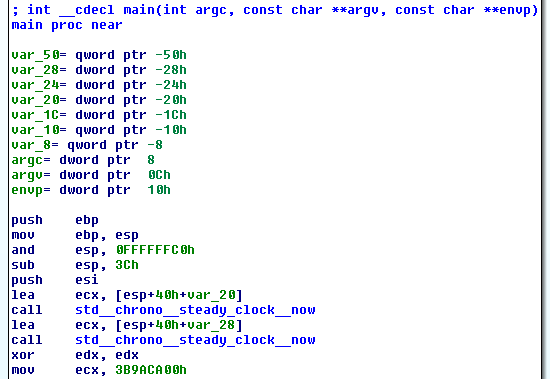
No wonder the code took almost no time — we’re simply measuring the time it takes to measure the lea instruction! The next section of code appeared to be the fib_iterative function:
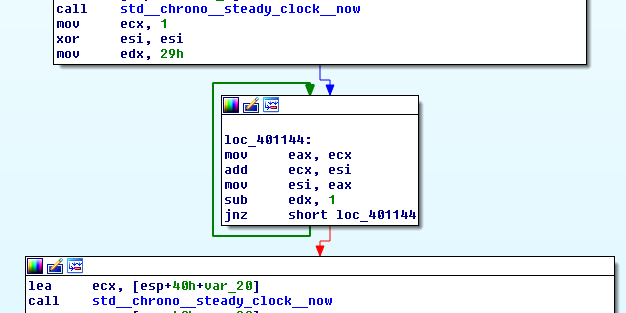
It would appear that a function pointer is no barrier to Visual Studio’s inlining; measure_execution_time never explicitly appears as a discrete subroutine. Regardless, the inlined assembly fib_iterative is about has straightforward as possible. Over on x64 the code appears even simpler (all code was compiled with /O2).
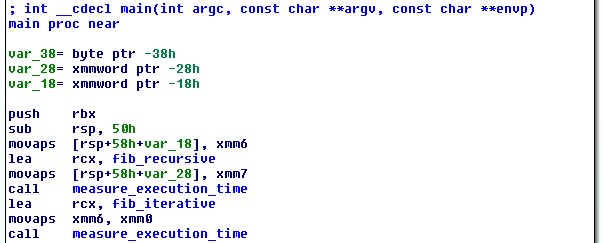
The function pointer inlining is gone, replaced with the more or less expected code, i.e. load the address of the function into an argument register and then call measure_execution_time .
So what’s the deal here? Where the heck did fib_recursive go on x86? I believe what we’re seeing is an unexpected application of dead code elimination. On Visual Studio the assert macro is #define assert(expression) ((void)0) in release mode, meaning the check that the return is equal to F_42 turns into nothing!
Since the return of fib_recursive (now) isn’t used, and the function itself simply does trivial math (besides calling itself), the compiler has decided it serves no purpose. What’s interesting is that the compiler did not make the same determination for fib_iterative . Given the choice between the two I would have assumed that fib_iterative , with its constant sized loop, would be easier to analyze than the recursive structure of fib_recursive . What’s even weirder is that this only happens on x86, not x64.
After modifying the code to display the the result of the functions with std::cout the problem went away. The moral of the story is that if you’re doing some performance unit testing make sure that your functions touch the outside world in some way; asserts aren’t always enough. Otherwise, the compiler may spontaneously decide to eliminate your code all together (and it may be platform dependent!), giving the illusion of incredible speed and cleverness on your part 🙂
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Leave a Reply