tl;dr FLAN-T5 (11B) scored identically to GPT-3.5 (text-davinci-003) across the ten publicly available SAT Reading Tests. A finetuned 3B model scored within 7 percentage points of GPT-3.5 on held-out tests with 98% less parameters while maintaining generalization
Models: base, large, xl, xxl Dataset: HuggingFace Code: GitHub
After working on literAI I’ve been interested in further exploring language models from a narrative/literary perspective. One question I had was “how well do these models actually ‘understand’ longer prose?”
Now, it just so happens that there’s a test we make teenagers take every year to determine this very fact! That is, the SAT (specifically, the Reading part).
The SAT Reading Test, despite its name, is multimodal. There is always one section that includes a combination of charts, tables, and graphs. However, the questions are clearly delineated — typically only three questions on the test reference the data. For the purposes of evaluation I excluded these questions. First, the results.
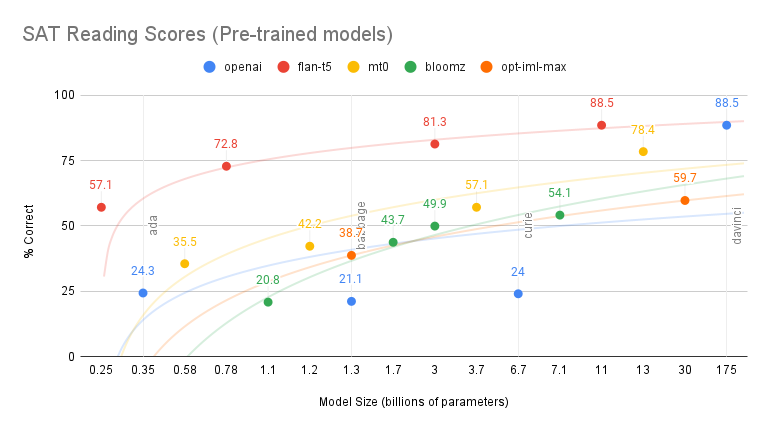
FLAN-T5 11B scored identical to GPT-3.5, despite being less than 1/10th the size! It is also can be run on a consumer GPU (<= 24 GB) when loaded in 8-bit inference mode! This offers further data supporting the hypothesis that Google did the open source local compute LM community a great service when it released FLAN-T5.
One interesting aspect of the SAT Reading Test is that 30% of the questions reference specific lines within the passage under consideration.
Which choice best supports the conclusion that
Mr. Peters wants to attract attention?A) Lines 80-81 (“Apparently… change”)
SAT Practice Test #5 Question #9
B) Lines 81-85 (“He straightened… hand”)
C) Lines 90-91 (“The young . . . Mr. Peters”)
D) Lines 91-93 (“He was… forty-five”)
As used in line 93, “becoming” most nearly means
A) emerging.
SAT Practice Test #5 Question #10
B) fitting.
C) developing.
D) happening.
This means that to properly answer the question the LM need to be able to count lines in the presented passage and reason about them explicitly in the context of the passage itself. The dataset I created faithfully represents the line breaks as they appear on the test. What it doesn’t contain is the extra line count helper column that appears next to the passage. For example, here is a snippet of what a passage on the actual test looks like:

Note the italicized Line and counter, which appears every five lines. Even the regular passages are multimodal! While it’s certainly just text, communicating it requires more than presenting it merely as a sequence of characters. To see how the models performed on these type of questions I took at look at how the best open source model (FLAN-T5) scored on the two question classes.
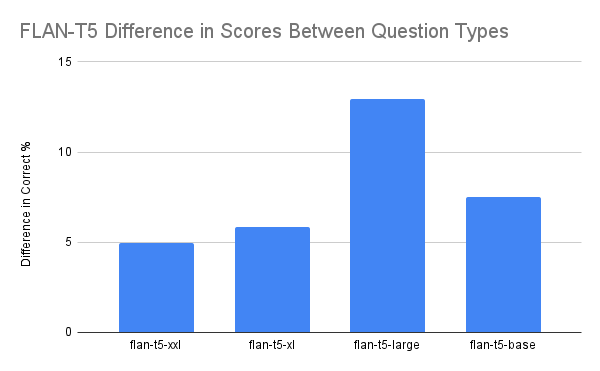
FLAN-T5 scored between 5-13% worse on the “line number” questions that it did on the other questions on the test. Could the model just need a little help counting?
To test this theory I finetuned the each of the FLAN-T5 models on eight of the ten practice tests, leaving the remaining two tests for validation. An especially huge thanks is in line to Philipp Schmid for his excellent blog posts on finetuning FLAN-T5.
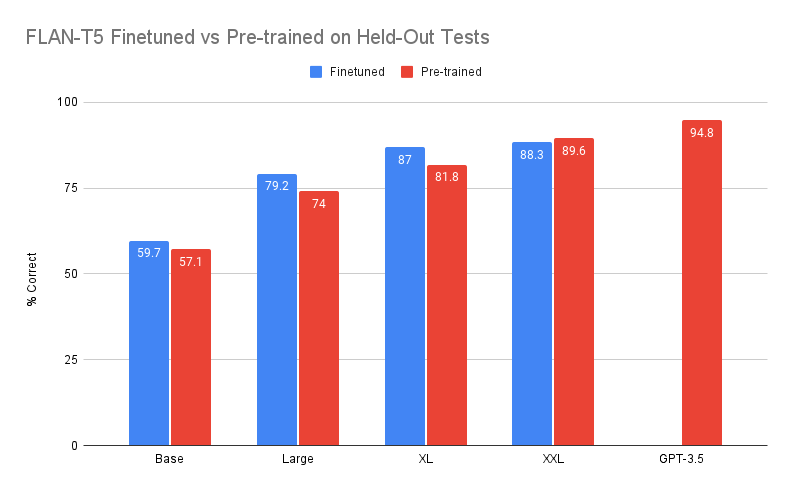
The models themselves are available here: base, large, xl, xxl. Three of the four finetuned models outscored the original models, with the XL model showing the largest gain. Of particular interest is the XL model, which is within seven percentage points of GPT-3.5 while having 98% (!!!) less parameters (3B vs. 175B).
One problem with aggressive finetuning on small datasets is overfitting or loss of generalization. Do the finetuned models still perform as well as the original models on unseen tasks? To test this I ran the finetuned on a subset of the SuperGLUE metrics.
| XXL PT | XL FT | XL PT | XL FT | Large PT | Large FT | Base PT | Base FT | |
|---|---|---|---|---|---|---|---|---|
| cb gpt | 0.87 | 0.83 | 0.83 | 0.83 | 0.76 | 0.71 | 0.82 | 0.82 |
| copa c1/c2 | 0.95 | 0.91 | 0.95 | 0.90 | 0.83 | 0.82 | 0.57 | 0.55 |
| rte gpt | 0.89 | 0.90 | 0.85 | 0.87 | 0.87 | 0.84 | 0.79 | 0.80 |
| wic gpt | 0.68 | 0.68 | 0.71 | 0.72 | 0.62 | 0.61 | 0.48 | 0.48 |
| wsc gpt | 0.76 | 0.77 | 0.73 | 0.75 | 0.66 | 0.61 | 0.45 | 0.46 |
The above table represents only a few of the hundreds of metrics ran — see the data for full results. They are, however, representative; the finetuned (FT) models maintain the same generalization capabilities as the pre-trained (PT) versions! It may be that the finetuned models are (by this limited measure) “better” than the originals since they score higher on the SAT Reading Test while maintaining zero-shot unseen task performance.
In conclusion, FLAN-T5 continues to show itself as a powerful model, both in its raw reasoning capabilities relative to closed source models, but also in its ability to quickly learn new skills through finetuning — not to mention its accessibility on consumer-grade hardware. ty google
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.